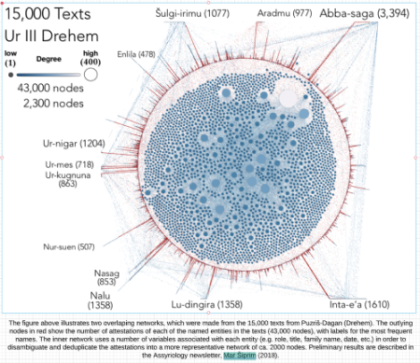
II. N-gram Neighbors of the Proper Names (PN)¶
Section II was made to add greater context to each PN.
Below are lists of professions, roles, and family relationships.
# import necessary libraries
import pandas as pd
from tqdm.auto import tqdm
# import libraries for this section
import re
1 Find Neighbors¶
Below we are making a copy of the filtered dataframe to manipulate and add the neighbors column.
The commented out line can be used if you have a copy of the words_df dataframe from the previous section and you would like to load that instead of running part I.
#words_df = pd.read_pickle('output/part_1_output.p') #uncomment to read from local file
words_df = pd.read_pickle('https://gitlab.com/yashila.bordag/sumnet-data/-/raw/main/part_1_output.p') # uncomment to read from online file
#List of professions, roles, family
professions = [ "aʾigidu[worker]",
"abala[water-drawer]",
"abrig[functionary]",
"ad.KID[weaver]",
"agaʾus[soldier]",
"arad[slave]",
"ašgab[leatherworker]",
"aʾua [musician]",
"azlag[fuller]",
"bahar[potter]",
"bisaŋdubak[archivist]",
"damgar[merchant]",
"dikud[judge]",
"dubsar[scribe]",
"en[priest]",
"erešdiŋir[priestess]",
"ensik[ruler]",
"engar[farmer]",
"enkud[tax-collector]",
"gabaʾaš[courier]",
"galamah[singer]",
"gala[singer]",
"geme[worker]",
"gudug[priest]",
"guzala[official]",
"idu[doorkeeper]",
"išib[priest]",
"kaguruk[supervisor]",
"kaš[runner]",
"kiŋgia[messenger]",
"kinda[barber]",
"kinkin[miller]",
"kiridab[driver]",
"kurušda[fattener]",
"kuš[official]",
"lu[person]",
"lugal[king]",
"lukur[priestess]",
"lungak[brewer]",
"malah[sailor]",
"muhaldim[cook]",
"mušendu[bird-catcher]",
"nagada[herdsman]",
"nagar[carpenter]",
"nar[musician]",
"nargal[musician]",
"narsa[musician]",
"nin[lady]",
"nubanda[overseer]",
"nukirik[horticulturalist]",
"saŋ.DUN₃[recorder]",
"saŋŋa[official]",
"simug[smith]",
"sipad[shepherd]",
"sukkal[secretary]",
"šabra[administrator]",
"šagia[cup-bearer]",
"šakkanak[general]",
# "szej[cook]", this is a verb
"šidim[builder]",
"šuʾi[barber]",
"šukud[fisherman]",
"tibira[sculptor]",
"ugula[overseer]",
"unud[cowherd]",
# "urin[guard]",
"UN.IL₂[menial]",
"ušbar[weaver]",
"zabardab[official]",
"zadim[stone-cutter]"]
roles = ['ki[source]', 'maškim[administrator]',
'maškim[authorized]', 'i3-dab5[recipient]', 'giri3[intermediary]']
family = ['šeš[brother]', 'szesz[brother]', 'dumu[son]', 'dumu-munus[daughter]',
'dumumunus[daughter]' , 'dam[spouse]']
def n_neighbors(data, n):
#create list to return, non-proper names will return empty lists
n_neighbors_list = [[] for i in range(len(data))]
#find list of all PN lemma indices
PN_index = data[data['lemma'].str.contains("PN")].index
#go through each tablet and find neighbors for each PN and add to list
for i in tqdm(PN_index, desc='N Neighbors'):
#find all lemma rows from the same tablet
group_of_same_pnumber = data[data['id_text'] == data.loc[i, 'id_text']]
#find all lemma rows from the n-gram range
group_of_n_lines_befaf = group_of_same_pnumber[((group_of_same_pnumber['id_line'] >= data.loc[i, 'id_line'] - n)
&(group_of_same_pnumber['id_line'] <= data.loc[i, 'id_line']))
| ((group_of_same_pnumber['id_line'] <= data.loc[i, 'id_line'] + n)
& (group_of_same_pnumber['id_line'] >= data.loc[i, 'id_line']))]
#create list of n-grams and remove breaks
lemma_neighbors = group_of_n_lines_befaf['lemma'].values.tolist()
if 'break' in lemma_neighbors:
lemma_neighbors.remove('break')
#add to final list
n_neighbors_list[i] = lemma_neighbors
return n_neighbors_list
words_df['prof?'] = words_df['lemma'].apply(lambda word: 'Yes' if (re.match('^[^\]]*', word)[0] + ']') in professions else 'No')
words_df['role?'] = words_df['lemma'].apply(lambda word: 'Yes' if (re.match('^[^\]]*', word)[0] + ']') in roles else 'No')
words_df['family?'] = words_df['lemma'].apply(lambda word: 'Yes' if (re.match('^[^\]]*', word)[0] + ']') in family else 'No')
#Create "number?"" to see if row is number. this could imply that that next row is a commodity
words_df['number?'] = words_df['lemma'].str.contains('NU')
words_df['number?'] = ['Yes' if words_df['number?'][i] == True else 'No' for i in words_df.index]
words_df['commodity?'] = ['No'] + ['Yes' if words_df['number?'][i] == 'Yes' else 'No' for i in words_df.index[1:]]
words_df
| lemma | id_text | id_line | id_word | label | date | dates_references | publication | collection | museum_no | ftype | metadata_source | prof? | role? | family? | number? | commodity? | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6(diš)[]NU | P100041 | 3 | P100041.3.1 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | Yes | No | |
| 1 | udu[sheep]N | P100041 | 3 | P100041.3.2 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | |
| 2 | kišib[seal]N | P100041 | 4 | P100041.4.1 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | |
| 3 | Lusuen[0]PN | P100041 | 4 | P100041.4.2 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | |
| 4 | ki[place]N | P100041 | 5 | P100041.5.1 | o 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 594695 | gud[ox]N | P481395 | 31 | P481395.31.2 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | No | No | |
| 594696 | 1(diš)[]NU | P481395 | 31 | P481395.31.3 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | Yes | Yes | |
| 594697 | anše[equid]N | P481395 | 31 | P481395.31.4 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | No | No | |
| 594698 | Šusuen[1]RN | P517012 | 3 | P517012.3.1 | a 1 | CDLI Seals 013964 (composite) | ORACC | No | No | No | No | No | |||||
| 594699 | Abumilum[0]PN | P517012 | 4 | P517012.4.1 | a 2 | CDLI Seals 013964 (composite) | ORACC | No | No | No | No | No |
594700 rows × 17 columns
The next code block takes a very long time to run.
List item
List item
#call n_neighbor function to get neighbors from two lines above and below
words_df['neighbors'] = n_neighbors(words_df, 2)
words_df
| lemma | id_text | id_line | id_word | label | date | dates_references | publication | collection | museum_no | ftype | metadata_source | prof? | role? | family? | number? | commodity? | neighbors | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6(diš)[]NU | P100041 | 3 | P100041.3.1 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | Yes | No | [] | |
| 1 | udu[sheep]N | P100041 | 3 | P100041.3.2 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [] | |
| 2 | kišib[seal]N | P100041 | 4 | P100041.4.1 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [] | |
| 3 | Lusuen[0]PN | P100041 | 4 | P100041.4.2 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [6(diš)[]NU, udu[sheep]N, kišib[seal]N, Lusuen... | |
| 4 | ki[place]N | P100041 | 5 | P100041.5.1 | o 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [] | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 579680 | gud[ox]N | P481395 | 31 | P481395.31.2 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | No | No | [] | |
| 579681 | 1(diš)[]NU | P481395 | 31 | P481395.31.3 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | Yes | Yes | [] | |
| 579682 | anše[equid]N | P481395 | 31 | P481395.31.4 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | No | No | [] | |
| 579683 | Šusuen[1]RN | P517012 | 3 | P517012.3.1 | a 1 | CDLI Seals 013964 (composite) | ORACC | No | No | No | No | No | [] | |||||
| 579684 | Abumilum[0]PN | P517012 | 4 | P517012.4.1 | a 2 | CDLI Seals 013964 (composite) | ORACC | No | No | No | No | No | [Šusuen[1]RN, Abumilum[0]PN] |
579685 rows × 18 columns
Check output only has neighbors for proper names.
words_df[words_df['lemma'].str.contains("PN")]
| lemma | id_text | id_line | id_word | label | date | dates_references | publication | collection | museum_no | ftype | metadata_source | prof? | role? | family? | number? | commodity? | neighbors | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | Lusuen[0]PN | P100041 | 4 | P100041.4.2 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [6(diš)[]NU, udu[sheep]N, kišib[seal]N, Lusuen... | |
| 5 | Abbakala[0]PN | P100041 | 5 | P100041.5.2 | o 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [6(diš)[]NU, udu[sheep]N, kišib[seal]N, Lusuen... | |
| 18 | UrKugnunak[0]PN | P100041 | 17 | P100041.17.1 | seal 1 ii 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [lugal[king]N, an[sky]N, anubda[quarter]N, lim... | |
| 33 | Ludiŋirak[0]PN | P100189 | 7 | P100189.7.2 | o 5 | SH46 - 08 - 05 | SH46 - 08 - 05 | AAS 211 | Louvre Museum, Paris, France | AO 20039 | BDTNS | No | No | No | No | No | [uš[die]V/i, ud[sun]N, 5(diš)-kam[]NU, ki[plac... | |
| 34 | Urniŋarak[0]PN | P100189 | 9 | P100189.9.1 | r 1 | SH46 - 08 - 05 | SH46 - 08 - 05 | AAS 211 | Louvre Museum, Paris, France | AO 20039 | BDTNS | No | No | No | No | No | [ki[place]N, Ludiŋirak[0]PN, Urniŋarak[0]PN, š... | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 579544 | Rabiʾili[0]PN | P459158 | 10 | P459158.10.1 | a ii 2 | Ibbi-Suen.00.00.00 | Ibbi-Suen.00.00.00 | CDLI Seals 006338 (physical) | private: anonymous, unlocated | Anonymous 459158 | ORACC | No | No | No | No | No | [lugal[king]N, an[sky]N, anubda[quarter]N, lim... | |
| 579571 | Dugazida[0]PN | P481391 | 10 | P481391.10.2 | r 1 | SH46 - 02 - 24 | SH46 - 02 - 24 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1950 | BDTNS | No | No | No | No | No | [uš[die]V/i, ud[sun]N, 2(u)[]NU, 4(diš)-kam[]N... | |
| 579573 | Urniŋarak[0]PN | P481391 | 11 | P481391.11.1 | r 2 | SH46 - 02 - 24 | SH46 - 02 - 24 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1950 | BDTNS | No | No | No | No | No | [ki[place]N, Dugazida[0]PN, kurušda[fattener]N... | |
| 579671 | Enlila[0]PN | P481395 | 27 | P481395.27.2 | r 8 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | No | No | [šuniŋin[total]N, 1(diš)[]NU, dusu[equid]N, ni... | |
| 579684 | Abumilum[0]PN | P517012 | 4 | P517012.4.1 | a 2 | CDLI Seals 013964 (composite) | ORACC | No | No | No | No | No | [Šusuen[1]RN, Abumilum[0]PN] |
53093 rows × 18 columns
words_df[~words_df['lemma'].str.contains("PN")]
| lemma | id_text | id_line | id_word | label | date | dates_references | publication | collection | museum_no | ftype | metadata_source | prof? | role? | family? | number? | commodity? | neighbors | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6(diš)[]NU | P100041 | 3 | P100041.3.1 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | Yes | No | [] | |
| 1 | udu[sheep]N | P100041 | 3 | P100041.3.2 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [] | |
| 2 | kišib[seal]N | P100041 | 4 | P100041.4.1 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [] | |
| 4 | ki[place]N | P100041 | 5 | P100041.5.1 | o 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [] | |
| 6 | zig[rise]V/i | P100041 | 6 | P100041.6.1 | o 4 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | No | No | No | No | No | [] | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 579679 | 2(u)[]NU | P481395 | 31 | P481395.31.1 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | Yes | Yes | [] | |
| 579680 | gud[ox]N | P481395 | 31 | P481395.31.2 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | No | No | [] | |
| 579681 | 1(diš)[]NU | P481395 | 31 | P481395.31.3 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | Yes | Yes | [] | |
| 579682 | anše[equid]N | P481395 | 31 | P481395.31.4 | l.e. 1 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | No | No | No | No | No | [] | |
| 579683 | Šusuen[1]RN | P517012 | 3 | P517012.3.1 | a 1 | CDLI Seals 013964 (composite) | ORACC | No | No | No | No | No | [] |
526592 rows × 18 columns
The following line confirms there are no rows where the lemma is not a Proper Noun and is given neighbors.
sum([lst != [] for lst in words_df[~words_df['lemma'].str.contains("PN")]['neighbors']])
0
2 Save Results in CSV file & Pickle¶
Here we will save the words_df output from parts 1 and 2.
words_df.to_csv('output/part_2_output.csv')
words_df.to_pickle('output/part_2_output.p')