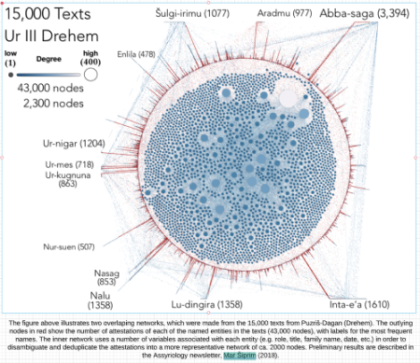
I. Importing the Data and Extracting Lemmatization from JSON¶
The code in this section will parse the ORACC JSON data of the Ur III corpus to extract lemmatization data.
The output contains text IDs, line IDs, lemmas, and relevant other data.
# import necessary libraries
import pandas as pd
# import libraries for this section
import requests
import zipfile
import json
# import libraries for workbook
# from tqdm.auto import tqdm
1 Import ORACC Data¶
We will begin by downloading the lemmatization data from ORACC. This will be downloaded in the form of zipped JSON files which we will parse in the next subsection and store in a pandas dataframe.
The ORACC database can be accessed via http://oracc.org/. The Ur III data can be viewed and interacted with at http://oracc.org/epsd2/admin/ur3.
To manipulated the data in this workbook however, we will need to download the data into our workspace and then parse and store this data in a pandas dataframe. We will download the data through a REST API using the requests library, and then store the data in a zipfile locally which will be parsed in the next section.
As we are accessing the JSON through the ORACC API, and the request URL is not the same as the viewing URL listed above. We will instead use: http://build-oracc.museum.upenn.edu/json/epsd2-admin-ur3.
If you are unfamiliar with using APIs and making HTTP requests and would like to learn how to do so in Python, this section of the Data 100 textbook might be helpful: http://www.textbook.ds100.org/ch/13/web_http.html
NOTE: If you already have this data, you can skip this step as it can take quite a long time.
# define the url to download from and name the zipfile to be created
url = 'http://build-oracc.museum.upenn.edu/json/epsd2-admin-ur3.zip'
file_name = 'jsonzip/epsd2-admin-ur3.zip'
# Workbook Code
'''
CHUNK = 1024 # Define chunk size
with requests.get(url, stream=True) as request:
if request.status_code == 200:
#if file is accessible, download
tqdm.write('Saving ' + url + ' as ' + file_name)
total_size = int(request.headers.get('content-length', 0))
tqdm_handler = tqdm(total=total_size, unit='B', unit_scale=True,
desc = 'epsd2/admin/ur3')
with open(file_name, 'wb') as zip_file:
#use tdqm to show download speed
for chunk in request.iter_content(chunk_size=CHUNK):
tqdm_handler.update(len(chunk))
zip_file.write(chunk)
else:
tqdm.write("WARNING: %s does not exist." % url)
'''
# Pedagogical Code
request = requests.get(url); # use a get request to get the data from the url
open(file_name, 'wb').write(request.content); # write data into zipfile
2 Download BTDNS Data¶
You can use the following instructions to obtain the data we need from the BDTNS database.
Go to http://bdtns.filol.csic.es/index.php?p=formulario_urIII.
In the Provenience drop down menu choose “Puzriš-Dagan” and hit “Search”. This will give a list of about 15,000 tablets from Drehem.
Now, hit “Export” on the left and in the pop-up window select every box except “Transliteration of the whole text(s)”. Hit “export”. This will produce a .txt file and you’ll need to put it into the “bdtns_metadata” folder.
The name of the .txt file changes everytime we download, so you may need to alter the code slightly to properly import the data in this notebook.
NOTE: The database’s downloading function is broken at the moment, however, so we will be using a previously obtained copy of the data hosted on our Github repository.
2.1 Extract Data from .txt file.¶
We have an existing copy of the data stored in a text file on our Github repository (https://github.com/niekveldhuis/sumnet/blob/master/QUERY_catalogue.txt).
As with the last subsection, we will be using an API to access our data, so the url is slightly different (https://raw.githubusercontent.com/niekveldhuis/sumnet/master/QUERY_catalogue.txt). Using pandas, we can actually download the data without the use of the requests library and can import the data into a pandas dataframe to work with it immediately.
The data is indexed both on BDTNS number ids and CDLI P-number ids. The ORACC data is indexed by P-numbers and so we will merge the data in the next subsection using these ids.
bdtns_catalogue_data = pd.read_csv('https://raw.githubusercontent.com/niekveldhuis/sumnet/master/QUERY_catalogue.txt', delimiter='\t')
# reset the index to the p numbers
bdtns_catalogue_data = bdtns_catalogue_data.set_index('CDLI_no')
bdtns_catalogue_data
| BDTNS_no | Publications | Museum_no | Date | Provenience | |
|---|---|---|---|---|---|
| CDLI_no | |||||
| NaN | 197624.0 | À l'école des scribes, p. 104 | NaN | AS09 - 00 - 00 | Umma |
| NaN | 203551.0 | A New Cuneiform Text..., IM 141866 | IM 141866 // | 0000 - 00 - 00 | Umma |
| P114469 | 21035.0 | AAA 1 78 24 = MVN 05 249 = CDLI P114469 | WML 49.47.46 | 0000 - 07 - 12 | Ĝirsu |
| P142651 | 38568.0 | AAICAB 1/1, Ashm. 1909-951 = CDLI P142651 | Ashm. 1909-951 | AS05 - 11 - 00 | Ĝirsu |
| P142652 | 38569.0 | AAICAB 1/1, Ashm. 1911-139 = CDLI P142652 | Ashm. 1911-139 | SS09 - 08 - 23 | Umma |
| ... | ... | ... | ... | ... | ... |
| P142619 | 6022.0 | ZVO 25 134 2 = Hermitage 3 195 (unpubl.) = CDL... | Erm 14814 | AS01 - 03 - 28 | Puzriš-Dagān |
| P142620 | 6023.0 | ZVO 25 136 3 = RA 73 190 = RIM E3/2.1.2.74 | MA 9612 | AS06 - 00 - 00 | Umma |
| NaN | 191925.0 | Zwischen Orient und Okzident 262 1 | NaN | AS03 - 00 - 00 | Umma |
| NaN | 191926.0 | Zwischen Orient und Okzident 264 2 | NaN | IS01 - 00 - 00 | Umma |
| P253713 | 170094.0 | NaN | MS 4703 | NaN | Unkn. Prov. |
101390 rows × 5 columns
2.2 Filtering Data¶
Here we are filtering the BDTNS data for Puzriš-Dagān tablets and drop tablets with null p-numbers or without dates. This will ensure we keep only the metadata relevant for our purposes.
# select for tablets from Puzriš-Dagān/Drehem
bdtns_catalogue_data = bdtns_catalogue_data[(bdtns_catalogue_data['Provenience']
=='Puzriš-Dagān') | (bdtns_catalogue_data['Provenience']
=='Puzriš-Dagān (?)')]
#select for non-null p_numbers and non-null dates
bdtns_catalogue_data = bdtns_catalogue_data.loc[~bdtns_catalogue_data.index.isnull(), :]
bdtns_catalogue_data = bdtns_catalogue_data[~bdtns_catalogue_data['Date'].isnull()]
bdtns_catalogue_data
| BDTNS_no | Publications | Museum_no | Date | Provenience | |
|---|---|---|---|---|---|
| CDLI_no | |||||
| P142785 | 38699.0 | AAICAB 1/1, Ashm. 1919-11a-b = CDLI P142785 = ... | Ashm. 1919-11a-b | IS01 - 08 - 00 | Puzriš-Dagān |
| P142787 | 38700.0 | AAICAB 1/1, Ashm. 1923-412 = CDLI P142787 | Ashm. 1923-412 | SS05 - 07 - 12 | Puzriš-Dagān |
| P142788 | 38701.0 | AAICAB 1/1, Ashm. 1923-415 = CDLI P142788 | Ashm. 1923-415 | SH48 - 12 - 20 | Puzriš-Dagān |
| P142789 | 38702.0 | AAICAB 1/1, Ashm. 1923-419 = CDLI P142789 | Ashm. 1923-419 | SS04 - XX - 15 | Puzriš-Dagān |
| P142790 | 38703.0 | AAICAB 1/1, Ashm. 1923-420 = CDLI P142790 | Ashm. 1923-420 | XXXX - 01//02 - 01 | Puzriš-Dagān |
| ... | ... | ... | ... | ... | ... |
| P141938 | 38553.0 | ZA 93 61 13 | GIS 13 | AS01 - 09 - 24 | Puzriš-Dagān |
| P274585 | 167818.0 | ZA 95 66 = CDLI P274585 | A 05505 | AS05 - XX - XX | Puzriš-Dagān |
| P381748 | 170855.0 | ZA 96 179 = HSAO 16, no. 083 | IM 044366 | XXXX - XX - XX | Puzriš-Dagān |
| P142618 | 6021.0 | ZVO 25 134 1 = Hermitage 3 174 (unpubl.) = CDL... | Erm 14811 | SH47 - 02 - 00 | Puzriš-Dagān |
| P142619 | 6022.0 | ZVO 25 134 2 = Hermitage 3 195 (unpubl.) = CDL... | Erm 14814 | AS01 - 03 - 28 | Puzriš-Dagān |
15279 rows × 5 columns
3 Parsing the Data¶
In this subsection we will merge the metadata we have on the Drehem tablets and parse the imported json data into a list we can later use to construct a pandas dataframe.
3.1 Getting the Metadata Data for the Tablets.¶
Before constructing our dataframe of lemmatized data, we will construct a dataframe of Drehem tablet metadata to filter and augment the data with.
We do this by loading the data from the catalogue.json into a dataframe and selecting the p-numbers where the provenience is indicated to be Puzriš-Dagan or modern Drehem. We will then replace the ORACC metadata with the BDTNS metadata where both databases have metadata and list the metadata source. Finally, we select the desired columns
# open the zipfile to read
zip_file = zipfile.ZipFile('jsonzip/epsd2-admin-ur3.zip')
#read and decode the project catalog json and store data in oracc_catalogue_json
oracc_json_str = zip_file.read('epsd2/admin/ur3/catalogue.json').decode('utf-8')
oracc_catalogue_json = json.loads(oracc_json_str)['members']
zip_file.close()
#create combined catalogue_data
oracc_catalogue_data = pd.DataFrame.from_dict(oracc_catalogue_json, orient='index')
catalogue_data = oracc_catalogue_data[(oracc_catalogue_data['provenience']
== 'Puzriš-Dagan (mod. Drehem)') |
oracc_catalogue_data.index.isin(bdtns_catalogue_data.index)]
#choose catalogue entries marked as Puzriš-Dagan in either ORACC or BDTNS
#add bdtns dates to oracc dataset and name metadata source
#added line to suppress setting with copy warning
pd.options.mode.chained_assignment = None # default='warn'
in_bdtns_index = catalogue_data.index.isin(bdtns_catalogue_data.index)
catalogue_data.loc[in_bdtns_index, 'date_of_origin'] = bdtns_catalogue_data['Date']
catalogue_data.loc[in_bdtns_index, 'dates_referenced'] = bdtns_catalogue_data['Date']
catalogue_data.loc[in_bdtns_index, 'provenience'] = bdtns_catalogue_data['Provenience']
catalogue_data['metadata_source'] = ['BDTNS' if in_bdtns else 'ORACC' for in_bdtns in in_bdtns_index]
#select necessary columns
catalogue_data = catalogue_data[['date_of_origin', 'dates_referenced', 'collection',
'primary_publication', 'museum_no', 'provenience',
'metadata_source']]
#display metadata
catalogue_data
| date_of_origin | dates_referenced | collection | primary_publication | museum_no | provenience | metadata_source | |
|---|---|---|---|---|---|---|---|
| P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | Louvre Museum, Paris, France | AAS 053 | AO 20313 | Puzriš-Dagān | BDTNS |
| P100189 | SH46 - 08 - 05 | SH46 - 08 - 05 | Louvre Museum, Paris, France | AAS 211 | AO 20039 | Puzriš-Dagān | BDTNS |
| P100190 | SH47 - 07 - 29 | SH47 - 07 - 29 | Louvre Museum, Paris, France | AAS 212 | AO 20051 | Puzriš-Dagān | BDTNS |
| P100191 | AS01 - 03 - 24 | AS01 - 03 - 24 | Louvre Museum, Paris, France | AAS 213 | AO 20074 | Puzriš-Dagān | BDTNS |
| P100211 | AS01 - 12 - 11 | AS01 - 12 - 11 | Museum of Fine Arts, Budapest, Hungary | ActSocHun Or 5-12, 156 2 | MHBA 51.2400 | Puzriš-Dagān | BDTNS |
| ... | ... | ... | ... | ... | ... | ... | ... |
| P456164 | NaN | NaN | NaN | CDLI Seals 003454 (composite) | NaN | Puzriš-Dagan (mod. Drehem) | ORACC |
| P459158 | Ibbi-Suen.00.00.00 | Ibbi-Suen.00.00.00 | private: anonymous, unlocated | CDLI Seals 006338 (physical) | Anonymous 459158 | Puzriš-Dagan (mod. Drehem) | ORACC |
| P481391 | SH46 - 02 - 24 | SH46 - 02 - 24 | Department of Classics, University of Cincinna... | unpublished unassigned ? | UC CSC 1950 | Puzriš-Dagān | BDTNS |
| P481395 | SS02 - 02 - 00 | SS02 - 02 - 00 | Department of Classics, University of Cincinna... | unpublished unassigned ? | UC CSC 1954 | Puzriš-Dagān | BDTNS |
| P517012 | NaN | NaN | NaN | CDLI Seals 013964 (composite) | NaN | Puzriš-Dagan (mod. Drehem) | ORACC |
15671 rows × 7 columns
3.2 The parse_ORACC_json() function¶
Here we define the parse_ORACC_json() function, which will recursively parse the json files provided by ORACC until it finds the relevant lemma data. It takes in the an ORACC json data structure, the associated meta_data, and some necessary keys and returns a list of lemma python dictionary entries which we can use to constuct a pandas dataframe.
The json files consist of a hierarchy of cdl nodes; only the nodes which have ‘f’ or ‘strict’ keys contain lemmatization data. The function goes down this hierarchy by recursively calling itself when a new cdl node is encountered. For more information about the data hierarchy in the ORACC json files, see ORACC Open Data.
We are left with lemma data dictionaries with a series of attributes:
id_text: consists of a project abbreviation, such asblmsorcams/gkabplus a text ID, in the formatcams/gkab/P338616ordcclt/Q000039.ftype: denotes if a node is a year name (yn) or not.word_id: consists of text ID, line ID, and word ID, in the formatQ000039.76.2ie. the second word in line 76 of text objectQ000039.label: human-legible label that refers to a line or another part of the text; eg.o i 23(obverse column 1 line 23) orr v 23'(reverse column 5 line 23 prime). Thelabelfield is used in online ORACC editions to indicate line numbers.extent,scope, andstate: gives metatextual data about the condition of the object; captures the number of broken lines or columns and similar information.date,dates_references,primary_publication,collection, andmuseum_no: metadata from the ORACC and BDTNS catalogues.
Note: 76 in the word_id is not a line number strictly speaking but an object reference within the text object. Things like horizontal rulings, columns, and breaks also get object references. The word_id field allows us to put lines, breaks, and horizontal drawings together in the proper order.
def parse_ORACC_json(lemmatized_data_json, meta_data, dollar_keys):
'''
A function to parse the ORACC json lemmatized data which has a specific
format outlined here: http://oracc.museum.upenn.edu/doc/opendata/json/index.html
This function recursively parses objects associated with the 'cdl' key to
extend the lemma_list. Each identified lemma's data is added as a new entry
in the lemma list, which is returned at the end of the function.
Inputs:
lemmatized_data_json: JSON object containing lemmatized data for a single
tablet from ORACC. Must be recursively called to
access lemma data. Lemma data objects can be
identified with the presence of an 'f' key or 'strict'
key
meta_data: a dictionary with various metadata fields pertaining to the given
tablet
dollar_keys: a list of keys used to add data to the 'strict' lemmas
Outputs:
lemma_list: a list of dictionaries where each entry corresponds to a single
lemma. This list is extended at the end of each recursion.
'''
lemma_list = []
for JSONobject in lemmatized_data_json['cdl']:
if 'cdl' in JSONobject:
lemma_list.extend(parse_ORACC_json(JSONobject, meta_data, dollar_keys))
if 'label' in JSONobject:
meta_data['label'] = JSONobject['label']
if 'f' in JSONobject:
lemma = JSONobject['f']
lemma['ftype'] = JSONobject.get('ftype')
lemma['id_word'] = JSONobject['ref']
lemma['label'] = meta_data['label']
lemma['id_text'] = meta_data['id_text']
lemma['date'] = meta_data['date']
lemma['dates_references'] = meta_data['dates_references']
lemma['publication'] = meta_data['publication']
lemma['collection'] = meta_data['collection']
lemma['museum_no'] = meta_data['museum_no']
lemma['metadata_source'] = meta_data['metadata_source']
lemma_list.append(lemma)
if 'strict' in JSONobject and JSONobject['strict'] == '1':
lemma = {key: JSONobject[key] for key in dollar_keys}
lemma['id_word'] = JSONobject['ref']
lemma['id_text'] = meta_data['id_text']
lemma['date'] = meta_data['date']
lemma['dates_references'] = meta_data['dates_references']
lemma['publication'] = meta_data['publication']
lemma['collection'] = meta_data['collection']
lemma['museum_no'] = meta_data['museum_no']
lemma['metadata_source'] = meta_data['metadata_source']
lemma_list.append(lemma)
return lemma_list
3.3 Call the parse_ORACC_json() function for every JSON file¶
Here we will use the parse_ORACC_json() and the catalogue dataframe to construct the words_df dataframe which we will be using throughout the rest of the code.
The project zip file downloaded earlier contains a directory that is called corpusjson that contains a JSON file for every text that is available in that corpus. The files are named using their text IDs in the pattern P######.json (or Q######.json or X######.json).
The function namelist() of the zipfile package is used to create a list of the names of all the files in the ZIP. From this list we select all the file names in the corpusjson directory with extension .json (this way we exclude the name of the directory itself).
Each of these files is read from the zip file and loaded with the command json.loads(), which transforms the string into a proper JSON object.
This JSON object (essentially a Python dictionary), which is called data_json is now sent to the parse_ORACC_json() function. The function adds lemmata to the lemm_l list. In the end, lemm_l will contain as many list elements as there are words in all the texts in the projects requested.
The dictionary meta_d is created to hold temporary information. The value of the key id_text is updated in the main process every time a new JSON file is opened and send to the parsejson() function. The parsejson() function itself will change values or add new keys, depending on the information found while iterating through the JSON file. When a new lemma row is created, parse_ORACC_json() will supply data such as id_text, label and (potentially) other information from meta_d.
lemma_list = []
meta_data = {'label': None}
dollar_keys = ['extent', 'scope', 'state']
try:
zip_file = zipfile.ZipFile(file_name) # create a Zipfile object
except:
print(file_name, 'does not exist or is not a proper ZIP file')
drehem_list_oracc = catalogue_data.index.to_list()
files = [project + '/corpusjson/' + p_number + '.json' for p_number in drehem_list_oracc] #that holds all the P, Q, and X numbers.
for lemma_file in tqdm(files, desc = project): #iterate over the file names
id_text = project + lemma_file[-13:-5] # id_text is, for instance, blms/P414332
p_number = lemma_file[-12:-5]
meta_data['id_text'] = id_text
meta_data['date'] = catalogue_data.loc[p_number]['date_of_origin']
meta_data['dates_references'] = catalogue_data.loc[p_number]['dates_referenced']
meta_data['publication'] = catalogue_data.loc[p_number]['primary_publication']
meta_data['collection'] = catalogue_data.loc[p_number]['collection']
meta_data['museum_no'] = catalogue_data.loc[p_number]['museum_no']
meta_data['metadata_source'] = catalogue_data.loc[p_number]['metadata_source']
try:
json_str = zip_file.read(lemma_file).decode('utf-8') #read and decode the json file of one particular text
lemmatized_data_json = json.loads(json_str) # make it into a json object (essentially a dictionary)
lemma_list.extend(parse_ORACC_json(lemmatized_data_json, meta_data, dollar_keys)) # and send to the parse_ORACC_json() function
except:
print(id_text, 'is not available or not complete')
zip_file.close()
4 Data Structuring¶
Here we construct our pandas dataframe.
4.1 Transform the Data into a DataFrame¶
Here we use lemma_list to make our dataframe and we view it.
words_df = pd.DataFrame(lemma_list)
words_df = words_df.fillna('') # fill empty values with empty strings
words_df[words_df['lang'] == 'sux'] # display lemmas where language is Sumerian
| lang | form | delim | gdl | pos | ftype | id_word | label | id_text | date | dates_references | publication | collection | museum_no | metadata_source | cf | gw | sense | norm0 | epos | base | morph | extent | scope | state | cont | aform | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sux | 6(diš) | [{'n': 'n', 'form': '6(diš)', 'id': 'P100041.3... | n | P100041.3.1 | o 1 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | ||||||||||||||
| 1 | sux | udu | [{'v': 'udu', 'id': 'P100041.3.2.0'}] | N | P100041.3.2 | o 1 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | udu | sheep | sheep | udu | N | udu | ~ | |||||||
| 2 | sux | kišib₃ | [{'v': 'kišib₃', 'id': 'P100041.4.1.0'}] | N | P100041.4.1 | o 2 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | kišib | seal | cylinder seal | kišib | N | kišib₃ | ~ | |||||||
| 3 | sux | lu₂-{d}suen | [{'v': 'lu₂', 'id': 'P100041.4.2.0', 'delim': ... | PN | P100041.4.2 | o 2 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | Lusuen | 0 | 0 | Lusuen | PN | lu₂-{d}suen | ~ | |||||||
| 4 | sux | ki | [{'v': 'ki', 'id': 'P100041.5.1.0'}] | N | P100041.5.1 | o 3 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | ki | place | place | ki | N | ki | ~ | |||||||
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 594695 | sux | gu₄ | [{'v': 'gu₄', 'id': 'P481395.31.2.0'}] | N | P481395.31.2 | l.e. 1 | epsd2/admin/ur3/P481395 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | gud | ox | bull, ox | gud | N | gud | ~ | |||||||
| 594696 | sux | 1(diš) | [{'n': 'n', 'form': '1(diš)', 'id': 'P481395.3... | n | P481395.31.3 | l.e. 1 | epsd2/admin/ur3/P481395 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | ||||||||||||||
| 594697 | sux | anše | [{'v': 'anše', 'id': 'P481395.31.4.0'}] | N | P481395.31.4 | l.e. 1 | epsd2/admin/ur3/P481395 | SS02 - 02 - 00 | SS02 - 02 - 00 | unpublished unassigned ? | Department of Classics, University of Cincinna... | UC CSC 1954 | BDTNS | anše | equid | equid, donkey | anše | N | anše | ~ | |||||||
| 594698 | sux | {d}šu-{d}suen | [{'det': 'semantic', 'pos': 'pre', 'seq': [{'v... | RN | P517012.3.1 | a 1 | epsd2/admin/ur3/P517012 | CDLI Seals 013964 (composite) | ORACC | Šusuen | 1 | 1 | Šusuen | RN | {d}šu-{d}suen | ~ | |||||||||||
| 594699 | sux | a-bu-um-dingir | [{'v': 'a', 'id': 'P517012.4.1.0', 'delim': '-... | PN | P517012.4.1 | a 2 | epsd2/admin/ur3/P517012 | CDLI Seals 013964 (composite) | ORACC | Abumilum | 0 | 0 | Abumilum | PN | a-bu-um-dingir | ~ |
588203 rows × 27 columns
words_df.shape # see shape
(594700, 27)
words_df.columns # see column names
Index(['lang', 'form', 'delim', 'gdl', 'pos', 'ftype', 'id_word', 'label',
'id_text', 'date', 'dates_references', 'publication', 'collection',
'museum_no', 'metadata_source', 'cf', 'gw', 'sense', 'norm0', 'epos',
'base', 'morph', 'extent', 'scope', 'state', 'cont', 'aform'],
dtype='object')
4.2 Remove Spaces and Commas from Guide Word and Sense¶
Spaces and commas in Guide Word and Sense may cause trouble in computational methods in tokenization, or when saved in Comma Separated Values format. All spaces and commas are replaced by hyphens and nothing (empty string), respectively.
By default the replace() function in pandas will match the entire string (that is, “lugal” matches “lugal” but there is no match between “l” and “lugal”). In order to match partial strings the parameter regex must be set to True.
The replace() function takes a nested dictionary as argument. The top-level keys identify the columns on which the replace() function should operate (in this case ‘gw’ and ‘sense’). The value of each key is another dictionary with the search string as key and the replace string as value.
findreplace = {' ' : '-', ',' : ''}
words_df = words_df.replace({'gw' : findreplace, 'sense' : findreplace}, regex=True)
The columns in the resulting DataFrame correspond to the elements of a full ORACC signature, plus information about text, line, and word ids:
base (Sumerian only)
cf (Citation Form)
cont (continuation of the base; Sumerian only)
epos (Effective Part of Speech)
form (transliteration, omitting all flags such as indication of breakage)
frag (transliteration; including flags)
gdl_utf8 (cuneiform)
gw (Guide Word: main or first translation in standard dictionary)
id_text (six-digit P, Q, or X number)
id_word (word ID in the format Text_ID.Line_ID.Word_ID)
label (traditional line number in the form o ii 2’ (obverse column 2 line 2’), etc.)
lang (language code, including sux, sux-x-emegir, sux-x-emesal, akk, akk-x-stdbab, etc)
morph (Morphology; Sumerian only)
norm (Normalization: Akkadian)
norm0 (Normalization: Sumerian)
pos (Part of Speech)
sense (contextual meaning)
sig (full ORACC signature)
(newly added) ftype (
ynif a node represents a year name)
Not all data elements (columns) are available for all words. Sumerian words never have a norm, Akkadian words do not have norm0, base, cont, or morph. Most data elements are only present when the word is lemmatized; only lang, form, id_word, and id_text should always be there.
We also included some metadata:
date
dates_references
primary_publication
collection
museum_no
The first two of which refer to the dates on the tablets and the last three of which refer to the current ownership and where the tablet was published.
4.3 Create Line ID¶
The DataFrame currently has a word-by-word data representation. We will add to each word a field id_line that will make it possible to reconstruct lines. This newly created field id_line is different from a traditional line number (found in the field “label”) in two ways. First, id_line is an integer, so that lines are sorted correctly. Second, id_line is assigned to words, but also to gaps and horizontal drawings on the tablet. The field id_line will allow us to keep all these elements in their proper order.
The field “id_line” is created by splitting the field “id_word” into (two or) three elements. The format of “id_word” is IDtext.line.word. The middle part, id_line, is selected and its data type is changed from string to integer. Rows that represent gaps in the text or horizontal drawings have an “id_word” in the format IDtext.line (consisting of only two elements), but are treated in exactly the same way.
words_df['id_line'] = [int(wordid.split('.')[1]) for wordid in words_df['id_word']]
words_df.head(10)
| lang | form | delim | gdl | pos | ftype | id_word | label | id_text | date | dates_references | publication | collection | museum_no | metadata_source | cf | gw | sense | norm0 | epos | base | morph | extent | scope | state | cont | aform | id_line | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sux | 6(diš) | [{'n': 'n', 'form': '6(diš)', 'id': 'P100041.3... | n | P100041.3.1 | o 1 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | 3 | ||||||||||||||
| 1 | sux | udu | [{'v': 'udu', 'id': 'P100041.3.2.0'}] | N | P100041.3.2 | o 1 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | udu | sheep | sheep | udu | N | udu | ~ | 3 | |||||||
| 2 | sux | kišib₃ | [{'v': 'kišib₃', 'id': 'P100041.4.1.0'}] | N | P100041.4.1 | o 2 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | kišib | seal | cylinder-seal | kišib | N | kišib₃ | ~ | 4 | |||||||
| 3 | sux | lu₂-{d}suen | [{'v': 'lu₂', 'id': 'P100041.4.2.0', 'delim': ... | PN | P100041.4.2 | o 2 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | Lusuen | 0 | 0 | Lusuen | PN | lu₂-{d}suen | ~ | 4 | |||||||
| 4 | sux | ki | [{'v': 'ki', 'id': 'P100041.5.1.0'}] | N | P100041.5.1 | o 3 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | ki | place | place | ki | N | ki | ~ | 5 | |||||||
| 5 | sux | ab-ba-kal-la-ta | [{'v': 'ab', 'id': 'P100041.5.2.0', 'delim': '... | PN | P100041.5.2 | o 3 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | Abbakala | 0 | 0 | Abbakala,ta | PN | ab-ba-kal-la | ~,ta | 5 | |||||||
| 6 | sux | ba-zi | [{'v': 'ba', 'id': 'P100041.6.1.0', 'delim': '... | V/i | P100041.6.1 | o 4 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | zig | rise | to-rise | ba:zig | V/i | zig₃ | ba:~ | 6 | |||||||
| 7 | P100041.8 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | n | space | blank | 8 | ||||||||||||||||
| 8 | P100041.9 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | 1 | impression | other | 9 | ||||||||||||||||
| 9 | sux | {d}šu-{d}suen | [{'det': 'semantic', 'pos': 'pre', 'seq': [{'v... | RN | P100041.12.1 | seal 1 i 1 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | Šusuen | 1 | 1 | Šusuen | RN | {d}šu-{d}suen | ~ | 12 |
5 Create Lemma Column¶
A lemma, ORACC style, combines Citation Form, GuideWord and POS into a unique reference to one particular lemma in a standard dictionary, as in lugal[king]N (Sumerian) or šarru[king]N.
Proper Nouns (proper names, geographical names, etc.) are a special case, because they currently receive a Part of Speech, but not a Citation Form or Guide Word.
Usually, not all words in a text are lemmatized, because a word may be (partly) broken and/or unknown. Unlemmatized and unlemmatizable words will receive a place-holder lemmatization that consists of the transliteration of the word (instead of the Citation Form), with NA as GuideWord and NA as POS, as in i-bu-x[NA]NA. Note that NA is a string.
Finally, rows representing horizontal rulings, blank lines, or broken lines have data in the fields ‘state’, ‘scope’, and ‘extent’ (for instance ‘state’ = broken, ‘scope’ = line, and ‘extent’ = 3, to indicate three broken lines). We can use this to prevent scripts to ‘jump over’ such breaks when looking for key words after (or before) a proper noun. We distinguish between physical breaks and logical breaks (such as horizontal rulings or seal impressions).
proper_nouns = ['FN', 'PN', 'DN', 'AN', 'WN', 'ON', 'TN', 'MN', 'CN', 'GN']
physical_break = ['illegible', 'traces', 'missing', 'effaced']
logical_break = ['other', 'blank', 'ruling']
words_df['lemma'] = words_df["cf"] + '[' + words_df["gw"] + ']' + words_df["pos"]
words_df.loc[words_df["cf"] == "" , 'lemma'] = words_df['form'] + '[NA]NA'
words_df.loc[words_df["pos"] == "n" , 'lemma'] = words_df['form'] + '[]NU'
#words_df.loc[words_df["pos"].isin(proper_nouns) , 'lemma'] = words_df['form'] + '[]' + words_df['pos']
words_df.loc[words_df["state"].isin(logical_break), 'lemma'] = "break_logical"
words_df.loc[words_df["state"].isin(physical_break), 'lemma'] = "break_physical"
words_df.head(10)
| lang | form | delim | gdl | pos | ftype | id_word | label | id_text | date | dates_references | publication | collection | museum_no | metadata_source | cf | gw | sense | norm0 | epos | base | morph | extent | scope | state | cont | aform | id_line | lemma | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | sux | 6(diš) | [{'n': 'n', 'form': '6(diš)', 'id': 'P100041.3... | n | P100041.3.1 | o 1 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | 3 | 6(diš)[]NU | ||||||||||||||
| 1 | sux | udu | [{'v': 'udu', 'id': 'P100041.3.2.0'}] | N | P100041.3.2 | o 1 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | udu | sheep | sheep | udu | N | udu | ~ | 3 | udu[sheep]N | |||||||
| 2 | sux | kišib₃ | [{'v': 'kišib₃', 'id': 'P100041.4.1.0'}] | N | P100041.4.1 | o 2 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | kišib | seal | cylinder-seal | kišib | N | kišib₃ | ~ | 4 | kišib[seal]N | |||||||
| 3 | sux | lu₂-{d}suen | [{'v': 'lu₂', 'id': 'P100041.4.2.0', 'delim': ... | PN | P100041.4.2 | o 2 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | Lusuen | 0 | 0 | Lusuen | PN | lu₂-{d}suen | ~ | 4 | Lusuen[0]PN | |||||||
| 4 | sux | ki | [{'v': 'ki', 'id': 'P100041.5.1.0'}] | N | P100041.5.1 | o 3 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | ki | place | place | ki | N | ki | ~ | 5 | ki[place]N | |||||||
| 5 | sux | ab-ba-kal-la-ta | [{'v': 'ab', 'id': 'P100041.5.2.0', 'delim': '... | PN | P100041.5.2 | o 3 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | Abbakala | 0 | 0 | Abbakala,ta | PN | ab-ba-kal-la | ~,ta | 5 | Abbakala[0]PN | |||||||
| 6 | sux | ba-zi | [{'v': 'ba', 'id': 'P100041.6.1.0', 'delim': '... | V/i | P100041.6.1 | o 4 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | zig | rise | to-rise | ba:zig | V/i | zig₃ | ba:~ | 6 | zig[rise]V/i | |||||||
| 7 | P100041.8 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | n | space | blank | 8 | break_logical | ||||||||||||||||
| 8 | P100041.9 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | 1 | impression | other | 9 | break_logical | ||||||||||||||||
| 9 | sux | {d}šu-{d}suen | [{'det': 'semantic', 'pos': 'pre', 'seq': [{'v... | RN | P100041.12.1 | seal 1 i 1 | epsd2/admin/ur3/P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | Šusuen | 1 | 1 | Šusuen | RN | {d}šu-{d}suen | ~ | 12 | Šusuen[1]RN |
6 Select Relevant Columns¶
Now we can select only the field ‘lemma’ and the fields that indicate the ID of the word, the line, or the document, plus the metadata, and the field ‘label’, which indicates the physical position of the line on the document.
cols = ['lemma', 'id_text', 'id_line', 'id_word', 'label', 'date', 'dates_references', 'publication', 'collection', 'museum_no', 'ftype', 'metadata_source']
words_df = words_df[cols].copy()
words_df.head(100)
| lemma | id_text | id_line | id_word | label | date | dates_references | publication | collection | museum_no | ftype | metadata_source | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6(diš)[]NU | epsd2/admin/ur3/P100041 | 3 | P100041.3.1 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 1 | udu[sheep]N | epsd2/admin/ur3/P100041 | 3 | P100041.3.2 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 2 | kišib[seal]N | epsd2/admin/ur3/P100041 | 4 | P100041.4.1 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 3 | Lusuen[0]PN | epsd2/admin/ur3/P100041 | 4 | P100041.4.2 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 4 | ki[place]N | epsd2/admin/ur3/P100041 | 5 | P100041.5.1 | o 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 95 | 1(diš)[]NU | epsd2/admin/ur3/P100211 | 3 | P100211.3.1 | o 1 | AS01 - 12 - 11 | AS01 - 12 - 11 | ActSocHun Or 5-12, 156 2 | Museum of Fine Arts, Budapest, Hungary | MHBA 51.2400 | BDTNS | |
| 96 | udu[sheep]N | epsd2/admin/ur3/P100211 | 3 | P100211.3.2 | o 1 | AS01 - 12 - 11 | AS01 - 12 - 11 | ActSocHun Or 5-12, 156 2 | Museum of Fine Arts, Budapest, Hungary | MHBA 51.2400 | BDTNS | |
| 97 | a[water]N | epsd2/admin/ur3/P100211 | 3 | P100211.3.3 | o 1 | AS01 - 12 - 11 | AS01 - 12 - 11 | ActSocHun Or 5-12, 156 2 | Museum of Fine Arts, Budapest, Hungary | MHBA 51.2400 | BDTNS | |
| 98 | x[NA]NA | epsd2/admin/ur3/P100211 | 3 | P100211.3.4 | o 1 | AS01 - 12 - 11 | AS01 - 12 - 11 | ActSocHun Or 5-12, 156 2 | Museum of Fine Arts, Budapest, Hungary | MHBA 51.2400 | BDTNS | |
| 99 | sag[rare]V/i | epsd2/admin/ur3/P100211 | 3 | P100211.3.5 | o 1 | AS01 - 12 - 11 | AS01 - 12 - 11 | ActSocHun Or 5-12, 156 2 | Museum of Fine Arts, Budapest, Hungary | MHBA 51.2400 | BDTNS |
100 rows × 12 columns
We can simplify the ‘id_text’ column, because all documents derive from the same project (epsd2/admin/u3adm).
words_df['id_text'] = [tid[-7:] for tid in words_df['id_text']]
words_df.head(20)
| lemma | id_text | id_line | id_word | label | date | dates_references | publication | collection | museum_no | ftype | metadata_source | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6(diš)[]NU | P100041 | 3 | P100041.3.1 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 1 | udu[sheep]N | P100041 | 3 | P100041.3.2 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 2 | kišib[seal]N | P100041 | 4 | P100041.4.1 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 3 | Lusuen[0]PN | P100041 | 4 | P100041.4.2 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 4 | ki[place]N | P100041 | 5 | P100041.5.1 | o 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 5 | Abbakala[0]PN | P100041 | 5 | P100041.5.2 | o 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 6 | zig[rise]V/i | P100041 | 6 | P100041.6.1 | o 4 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 7 | break_logical | P100041 | 8 | P100041.8 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | ||
| 8 | break_logical | P100041 | 9 | P100041.9 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | ||
| 9 | Šusuen[1]RN | P100041 | 12 | P100041.12.1 | seal 1 i 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 10 | lugal[king]N | P100041 | 13 | P100041.13.1 | seal 1 i 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 11 | kalag[strong]V/i | P100041 | 13 | P100041.13.2 | seal 1 i 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 12 | lugal[king]N | P100041 | 14 | P100041.14.1 | seal 1 i 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 13 | Urim[1]SN | P100041 | 14 | P100041.14.2 | seal 1 i 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 14 | lugal[king]N | P100041 | 15 | P100041.15.1 | seal 1 i 4 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 15 | an[sky]N | P100041 | 15 | P100041.15.2 | seal 1 i 4 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 16 | anubda[quarter]N | P100041 | 15 | P100041.15.3 | seal 1 i 4 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 17 | limmu[four]NU | P100041 | 15 | P100041.15.4 | seal 1 i 4 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 18 | UrKugnunak[0]PN | P100041 | 17 | P100041.17.1 | seal 1 ii 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 19 | dubsar[scribe]N | P100041 | 18 | P100041.18.1 | seal 1 ii 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS |
test = words_df.head(4000)
test[test['lemma'].str.contains('N')]
| lemma | id_text | id_line | id_word | label | date | dates_references | publication | collection | museum_no | ftype | metadata_source | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6(diš)[]NU | P100041 | 3 | P100041.3.1 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 1 | udu[sheep]N | P100041 | 3 | P100041.3.2 | o 1 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 2 | kišib[seal]N | P100041 | 4 | P100041.4.1 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 3 | Lusuen[0]PN | P100041 | 4 | P100041.4.2 | o 2 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| 4 | ki[place]N | P100041 | 5 | P100041.5.1 | o 3 | SSXX - 00 - 00 | SSXX - 00 - 00 | AAS 053 | Louvre Museum, Paris, France | AO 20313 | BDTNS | |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3995 | Inabanum[0]PN | P100981 | 4 | P100981.4.1 | o 2 | AS05 - 04 - 20 | AS05 - 04 - 20 | Amorites 16 | Oriental Institute, University of Chicago, Chi... | OIM A02868 | BDTNS | |
| 3996 | MAR.TU[westerner]N | P100981 | 4 | P100981.4.2 | o 2 | AS05 - 04 - 20 | AS05 - 04 - 20 | Amorites 16 | Oriental Institute, University of Chicago, Chi... | OIM A02868 | BDTNS | |
| 3997 | 1(diš)[]NU | P100981 | 5 | P100981.5.1 | o 3 | AS05 - 04 - 20 | AS05 - 04 - 20 | Amorites 16 | Oriental Institute, University of Chicago, Chi... | OIM A02868 | BDTNS | |
| 3998 | sila[lamb]N | P100981 | 5 | P100981.5.2 | o 3 | AS05 - 04 - 20 | AS05 - 04 - 20 | Amorites 16 | Oriental Institute, University of Chicago, Chi... | OIM A02868 | BDTNS | |
| 3999 | Urištaran[0]PN | P100981 | 6 | P100981.6.1 | o 4 | AS05 - 04 - 20 | AS05 - 04 - 20 | Amorites 16 | Oriental Institute, University of Chicago, Chi... | OIM A02868 | BDTNS |
3465 rows × 12 columns
7 Save Results in CSV file & Pickle¶
The output file is called part_1_output.csv and is placed in the directory output. In most computers, csv files open automatically in Excel. This program does not deal well with utf-8 encoding (files in utf-8 need to be imported; see the instructions here. If you intend to use the file in Excel, change encoding ='utf-8' to encoding='utf-16'. For usage in computational text analysis applications utf-8 is usually preferred.
The Pandas function to_pickle() writes a binary file that can be opened in a later phase of the project with the read_pickle() command and will reproduce exactly the same DataFrame with the same data structure. The resulting file can only be used by pandas.
You can skip Part I by importing the Part I output as a pandas dataframe at the beginning of Part II. Similarly, in the next parts, after you save the output, you will be able to import that output later on instead of rerunning the sections before.
catalogue_data.reset_index()
| index | date_of_origin | dates_referenced | collection | primary_publication | museum_no | provenience | metadata_source | |
|---|---|---|---|---|---|---|---|---|
| 0 | P100041 | SSXX - 00 - 00 | SSXX - 00 - 00 | Louvre Museum, Paris, France | AAS 053 | AO 20313 | Puzriš-Dagān | BDTNS |
| 1 | P100189 | SH46 - 08 - 05 | SH46 - 08 - 05 | Louvre Museum, Paris, France | AAS 211 | AO 20039 | Puzriš-Dagān | BDTNS |
| 2 | P100190 | SH47 - 07 - 29 | SH47 - 07 - 29 | Louvre Museum, Paris, France | AAS 212 | AO 20051 | Puzriš-Dagān | BDTNS |
| 3 | P100191 | AS01 - 03 - 24 | AS01 - 03 - 24 | Louvre Museum, Paris, France | AAS 213 | AO 20074 | Puzriš-Dagān | BDTNS |
| 4 | P100211 | AS01 - 12 - 11 | AS01 - 12 - 11 | Museum of Fine Arts, Budapest, Hungary | ActSocHun Or 5-12, 156 2 | MHBA 51.2400 | Puzriš-Dagān | BDTNS |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 15666 | P456164 | NaN | NaN | NaN | CDLI Seals 003454 (composite) | NaN | Puzriš-Dagan (mod. Drehem) | ORACC |
| 15667 | P459158 | Ibbi-Suen.00.00.00 | Ibbi-Suen.00.00.00 | private: anonymous, unlocated | CDLI Seals 006338 (physical) | Anonymous 459158 | Puzriš-Dagan (mod. Drehem) | ORACC |
| 15668 | P481391 | SH46 - 02 - 24 | SH46 - 02 - 24 | Department of Classics, University of Cincinna... | unpublished unassigned ? | UC CSC 1950 | Puzriš-Dagān | BDTNS |
| 15669 | P481395 | SS02 - 02 - 00 | SS02 - 02 - 00 | Department of Classics, University of Cincinna... | unpublished unassigned ? | UC CSC 1954 | Puzriš-Dagān | BDTNS |
| 15670 | P517012 | NaN | NaN | NaN | CDLI Seals 013964 (composite) | NaN | Puzriš-Dagan (mod. Drehem) | ORACC |
15671 rows × 8 columns
words_df.to_csv('output/part_1_output.csv')
words_df.to_pickle('output/part_1_output.p')
catalogue_data.to_csv('output/part_1_catalogue.csv')
catalogue_data.to_pickle('output/part_1_catalogue.p')